04. Absolute vs. Relative Frequency
L3 041 Absolute V Relative Frequency V5
DataVis L3 04 V2
(Note: Towards the end of the video, the text labeling works since the bars have been sorted by frequency. For a more general method, see the section at the bottom of this page.)
Absolute vs. Relative Frequency
By default, seaborn's
countplot
function will summarize and plot the data in terms of
absolute frequency
, or pure counts. In certain cases, you might want to understand the distribution of data or want to compare levels in terms of proportions of the whole. In this case, you will want to plot the data in terms of
relative frequency
, where the height indicates the proportion of data taking each level, rather than the absolute count.
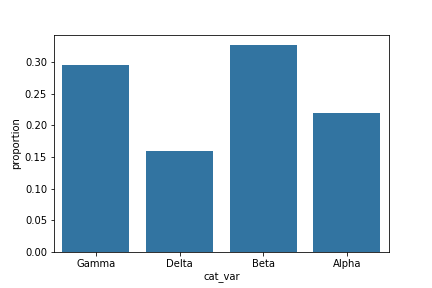
One method of plotting the data in terms of relative frequency on a bar chart is to just relabel the counts axis in terms of proportions. The underlying data will be the same, it will simply be the scale of the axis ticks that will be changed.
# get proportion taken by most common group for derivation
# of tick marks
n_points = df.shape[0]
max_count = df['cat_var'].value_counts().max()
max_prop = max_count / n_points
# generate tick mark locations and names
tick_props = np.arange(0, max_prop, 0.05)
tick_names = ['{:0.2f}'.format(v) for v in tick_props]
# create the plot
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)
plt.yticks(tick_props * n_points, tick_names)
plt.ylabel('proportion')
The
xticks
and
yticks
functions aren't only about rotating the tick labels. You can also get and set their locations and labels as well. The first argument takes the tick locations: in this case, the tick proportions multiplied back to be on the scale of counts. The second argument takes the tick names: in this case, the tick proportions formatted as strings to two decimal places.
I've also added a
ylabel
call to make it clear that we're no longer working with straight counts.
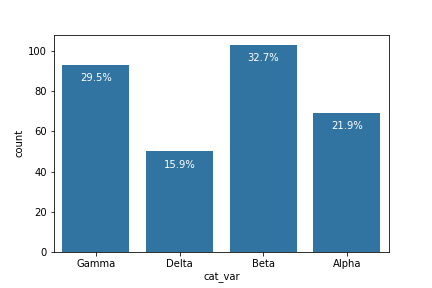
Additional Variation
Rather than plotting the data on a relative frequency scale, you might use text annotations to label the frequencies on bars instead. This requires writing a loop over the tick locations and labels and adding one text element for each bar.
# create the plot
base_color = sb.color_palette()[0]
sb.countplot(data = df, x = 'cat_var', color = base_color)
# add annotations
n_points = df.shape[0]
cat_counts = df['cat_var'].value_counts()
locs, labels = plt.xticks() # get the current tick locations and labels
# loop through each pair of locations and labels
for loc, label in zip(locs, labels):
# get the text property for the label to get the correct count
count = cat_counts[label.get_text()]
pct_string = '{:0.1f}%'.format(100*count/n_points)
# print the annotation just below the top of the bar
plt.text(loc, count-8, pct_string, ha = 'center', color = 'w')
I use the
.get_text()
method to obtain the category name, so I can get the count of each category level. At the end, I use the
text
function to print each percentage, with the x-position, y-position, and string as the three main parameters to the function.
(Documentation: Text objects )